
Developing trustworthy information
Trustworthy information is developed, not just moved and reformatted.
I’d add it’s also tested, and reviewed where possible, but all this seems like “it goes without saying.” Except it’s 2026 and it doesn’t go without saying. 🤖 So here I am saying the thing I think about whenever I see someone post blithely about a new docs automation tool.
I debated long whether this post was really worth writing. But I’ve heard too many people (it seems like they’re new to docs development & maintenance work) promote their “docs” tools in a way that sounds like the main challenge is primarily moving existing information and reformatting it in an automated workflow. (By the way, automating SDK and API docs updates existed well before AI workflows went mainstream and still involved human oversight and reviewers.)
Here are some key parts to developing trustworthy information that are frequently overlooked or misunderstood.
The original context keepers
So much depends on what information you start out with, how much it changes, and how much it can be trusted.
A technical writer is often the first person outside of the engineering and design team in the trenches of how a software product works for the end user. (Not just how it was meant to work.) If you work in an organization that is primarily engineering-led, you may be the first person outside of the engineering team to encounter how the product works for the end user.
Like many tech writers, I once had a manager who didn’t really understand my role. I was told I should review the docs PR for a major platform release, change some words, and “make it accurate.”
I saw a lot of risks with that approach for this particular product area, though, so I asked for more context to get to the bottom of “why” my manager thought this was the best approach. I was able to make a case for the unique value I could bring to this process compared to the risks, given the expertise I built up in this product area over time.
If I could go back in time, I’d use this image I originally hand-sketched a while ago to show my old manager. I reworked it to be more legible. No AI was used to craft this! I left some human details in there.
This image also helps explain why I think technical writers are the OG Context Keepers.
Here’s how tech writers (or Context Keepers/Information Developers/whatever they’re called these days) can make experiences accurate, usable, optimal, and successful.
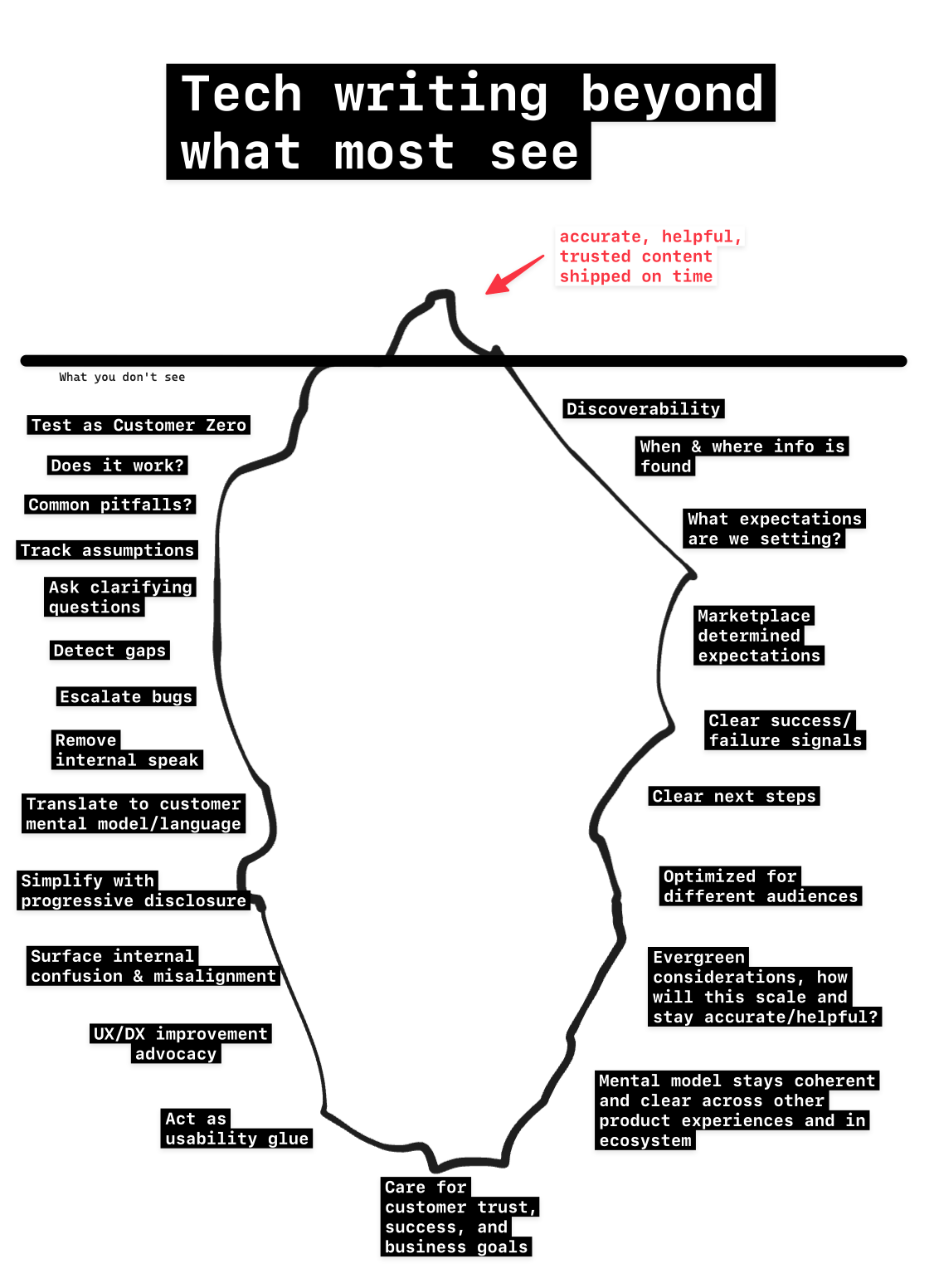
The secret is human-earned context and care 🤫
The secret of how tech writers develop trustworthy information is that they practice genuine care for the end-to-end experience, learn the product experience inside and out (even if they start as an outsider), and build context that you can’t just get from writing.
This is “earned” context through building trust across other teams and stakeholders and through shipping successful (and unsuccessful) products in different environments and working cultures.
Tech writers (or whatever they’re called these days) are paid to develop (and maintain) trustworthy information, not just move it around. Automation can help with maintaining trustworthy information but it’s not all that technical writers do.
Earning or developing context well also takes real skills and demands a certain kind of character.
Skills & traits for developing trustworthy information
- Asking the right questions in the right way in the right place and at the right time. It’s no accident that some of the best technical writers I’ve worked with used to work as journalists.
- Constantly tracking what you know and don’t know with intellectual humility and rigor (Stay tuned for my future “Assumption Tracker app!”)
- Facilitating discussions to help surface internal confusion, misalignments, and other kinds of conversation debt
- Evaluating the trustworthiness of information
- Evaluating what others know, what product language world they live in, and what they don’t know
- Intellectual humility, honesty, and rigor
Accuracy as a moving target
The last challenge for developing trustworthy information I want to explore is that the source of “truth” is often a moving target.
The degree of movement, of course, depends on your working environment, but there are really too many factors to explore there without writing another post.
It takes some nimble work to account for all the last-minute changes of software product launches:
- the multiple product name changes
- the new conflict with an existing reserved term
- the last-minute security bug fix to work around
- the delicate balance to be found between internal disagreement
- the purging of confusing internal product language
- the “everyone is too busy to review anything” but make sure this launches and lands successfully
- Does the last minute bug in your testing reveal an undocumented dependency? Or is it just an internal edge case your end users won’t experience in production?
There’s much more that could be written about the “human layer” of developing trustworthy information, but this post offers a starting point.
And you?
What are your takes on the job of developing trustworthy information? I know I’ve left some things out of the image I developed too. Part of this is intentional, lest the next docs AI automation tools pretend they can do it all, but if you want to have a human chat about this, let’s do it. You can reach out to me on a moderated platform, such as LinkedIn or Blue Sky.